Section 2Overview of the PDF file format
PDF files normally come employing a certain amount of compression, to reduce file-size, so appear to be totally intractable to reading by a human. Software techniques exist to undo the compression, or the PDF file may have been created without using any. The example document\Exfootmark\ was created without compression, so can be opened for reading in most editing software.
The overall structure of an uncompressed PDF file consists of:
- a collection of numbered objects: written as
<num> 0 obj…endobjwhere the ` …' can represent many, many lines of textual (or binary) data starting on a new line afterobjand withendobjon a line by itself. The numbering need not be sequential and objects may appear in any order. An indirect reference sequence of the form<num> 0 R†† is used where data from one object is required when processing another. A cross-reference table (described next), allows an object and its data to be located precisely. Such indirect references are evident throughout the coding portions of Figures 2.1– 3.2.2. - the cross-reference table: listing of byte-offsets to where each numbered object occurs within the uncompressed PDF file, together with a linked listing of unused object numbers. (Unused numbers are available for use by PDF editing software.)
- the trailer, including:
- total number of objects used;
- reference to the document's /Catalog, see Fig. \subfigref{3c};
- reference to the /Info dictionary, containing file properties (i.e., basic metadata);
- byte-offset to the cross-reference table;
- encryption and decryption keys for handling compression;
- end-of-file marker.
Thus the data in a PDF file is contained within the collection of objects, using the cross-reference table to precisely locate those objects. A PDF browser uses the /Catalog object (e.g., object 2081 in Fig. \subfigref{3c}) to find the list of /Page objects (e.g., object 5 in Fig. \subfigref{3b}), each of which references a /Contents object. This provides each page's contents stream of graphics commands, which give the details of how to build the visual view of the content to be displayed. A small portion of the page stream for a particular page is shown in Figures \subfigref{1b}, \subfigref{3a}, \subfigref{5a}.
Character strings are used in PDF files in various ways;
most commonly for ASCII strings, in the form ( …); see
Figures \subfigref{1a}, \subfigref{1b},
\subfigref{2b}, \subfigref{2c},
\subfigref{3a}, \subfigref{3c},
and \subfigref{5a}.
Alternatively, a hexadecimal representation with byte-order mark < FEFF…> can be used,
as in Figures \subfigref{1b},
\subfigref{3a},
\subfigref{5a}.
This is required particularly for Unicode characters above position 255,
with `surrogate pairs' used for characters outside the basic plane, as with the \(k\) variable name in those figures.
Below 255 there is also the possibility of using 3-byte octal codes within the ( …) string format;
see \Octalfootmark in Sect. 4.
For full details, see §7.3.4 of PDF Specifications [PDF17, ISO32000].
PDF names of the form /\(\BNF{name}\), usually using ordinary letters, have a variety of uses, including
- tag-names in the content stream (Figures \subfigref{1b}, \subfigref{3a}, \subfigref{5a});
- identifiers for named resources (Fig. \subfigref{3b} within object 20 and in the /AF tagging shown in Fig. \subfigref{3a}); and extensively as
- dictionary keys (in all the Figures 2.1, 2.1.1, 3.1, 3.2.2) and frequently as dictionary values (see below).
Other common structures used within PDF objects are as follows.
- arrays, represented as
[\(\BNF{item}\ \BNF{item}\ \ldots\ \BNF{item}\)], usually with similar kinds of \(\BNF{item}\), (see e.g., Figures \subfigref{1a}, \subfigref{3b}, \subfigref{3c}) or alternating kinds (e.g., the filenames array of Fig. \subfigref{2b}. - dictionaries
of key–value pairs, similar to alternating arrays, but represented as
< <\(\BNF[_1]{key}\ \BNF[_1]{value}\ \BNF[_2]{key}\ \BNF[_2]{value}\) …>>. The \(\BNF{key}\) is always a PDF name whereas the \(\BNF{value}\) may be any other element (e.g., string, number, name, array, dictionary, indirect reference). The key–value pairs may occur in any order, with the proviso that if the same \(\BNF{key}\) occurs more than once, it is the first instance whose \(\BNF{value}\) is used. A /Type key, having a PDF name as value, is not always mandatory; but when given, one refers to the dictionary object as being of the type of this name. See Figures \subfigref{1a}, \subfigref{2b}, \subfigref{2c}, \subfigref{3b}, \subfigref{3c} and \subfigref{5b} for examples. - stream objects
consist of a dictionary followed by an arbitrarily-long delimited stream of data,
having the form
< < … >> stream … endstream, with thestreamandendstreamkeywords each being on a separate line by themselves (see objects 26 and 28 in Fig. \subfigref{2c}). The dictionary must include a /Length key, whose value is the integer number of bytes within the data-stream. With the length of the data known, between the keywords on separate lines, there is no need for any escaping or special encoding of any characters, as is frequently needed in other circumstances and file-formats. See §7.3.8 of [PDF17, ISO32000] for more details; e.g., how compression can be used. - graphics operators which place font characters into the visual view
occur inside a page contents stream,
within portions delimited by
BT…ET(abbreviations for Begin/End Text); see Figures \subfigref{1b}, \subfigref{3a}, \subfigref{5a}. These include coding /\(\BNF{fontname}\ \BNF{size}\)Tffor selecting the (subsetted) font, scaled to a particular size, and[\(\BNF{string}\)]TJfor setting the characters of the string with the previously selected font. See §9.4 of [PDF17, ISO32000] for a complete description of the available text-showing and text-positioning operators.
Dictionaries and arrays can be nested; that is, the \(\BNF{value}\) of a dictionary item's \(\BNF{key}\) may well be another dictionary or array, as seen in objects 20 and 90 within Fig. \subfigref{3b}. Similarly one or more \(\BNF{item}\)s in an array could well be a dictionary, another array, or an indirect reference (regarded as a `pointer' to another object).
With the use of PDF names, objects, and indirect references a PDF file is like a self-contained web of interlinked information, with names chosen to indicate the kind of information referenced or how that information should be used.
The use of objects, dictionaries (with key–value pairs) and indirect references makes for a very versatile container-like file format. If PDF reader software does not recognise a particular key occurring within a particular type of dictionary, then both the key and its value are ignored. When that value is an indirect reference to another object, such as a stream object, then the data of that stream may never be processed, so does not contribute to the view being built. Thus PDF producing or editing software may add whatever objects it likes, for its own purposes, without affecting the views that other PDF reading software wish to construct. This should be contrasted with HTML and XML when a browser does not recognise a custom tag. There that tag is ignored, together with its attributes, but any content of that tag must still be handled.
It is this feature of the PDF language which allows different reader software to support different features, and need not use all of the information contained within a PDF file. For example, some browsers support attachments; others do not. A PDF format specification now consists mostly of saying which tags and dictionary keys must be present, what others are allowed, and how the information attached to these keys and tags is intended to be used. Hence the proliferation of different standards: PDF/A, PDF/E, PDF/VT, PDF/UA, PDF/X, perhaps with several versions or revisions, intended for conveying different kinds of specialised information most relevant within specific contexts.
 \setbox0=\kern-10pt\lower\ht0\box0
\ht0=0pt \dp0=0pt \box0
\setbox0=\vbox{\hsize=\linewidth
{\scriptsize
\begin{multicols}2
\setbox0=\kern-10pt\lower\ht0\box0
\ht0=0pt \dp0=0pt \box0
\setbox0=\vbox{\hsize=\linewidth
{\scriptsize
\begin{multicols}2
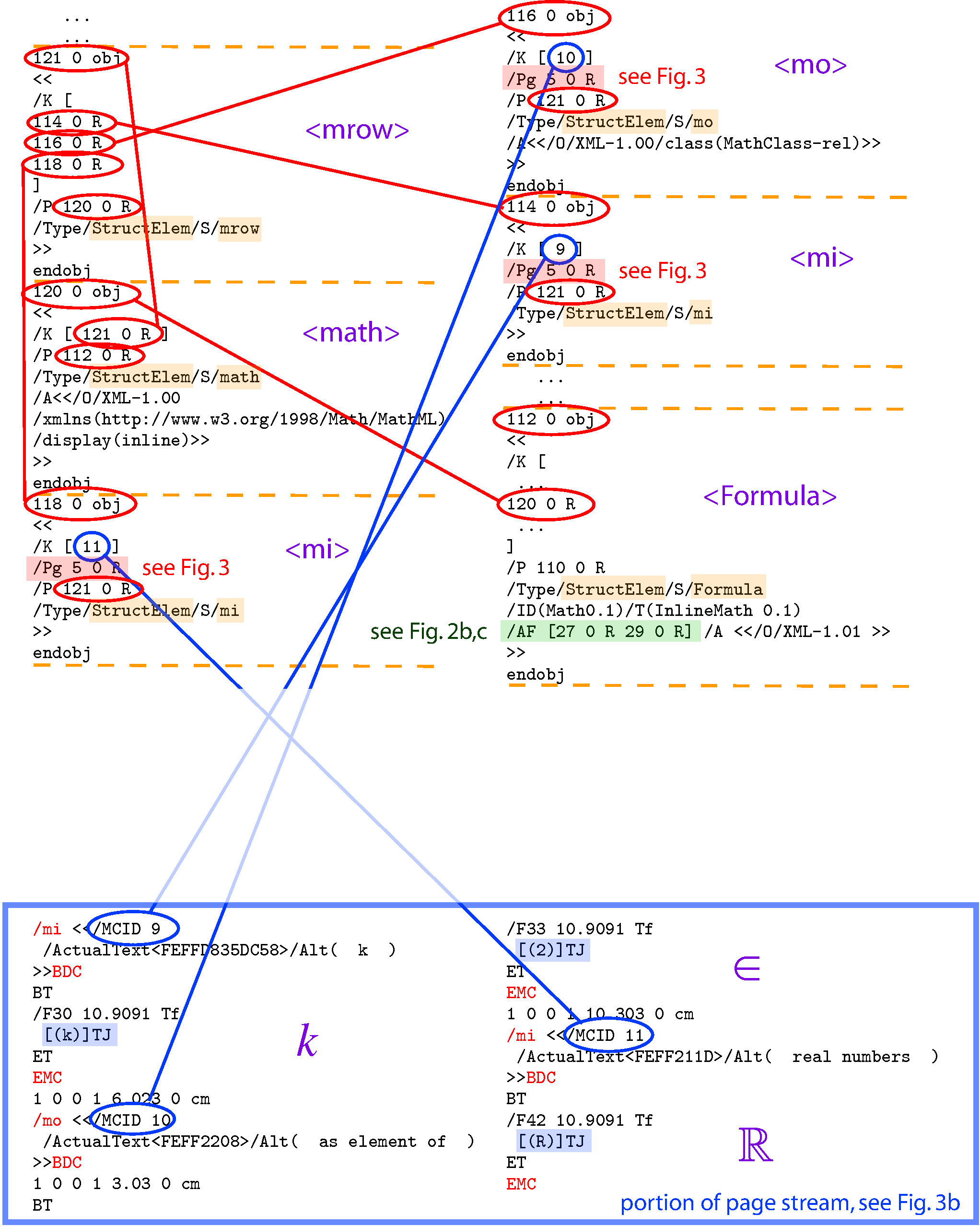
... ... 121 0 obj << /K [ 114 0 R 116 0 R 118 0 R ] /P 120 0 R /Type/StructElem/S/mrow >> endobj 120 0 obj << /K [ 121 0 R ] /P 112 0 R /Type/StructElem/S/math /A<> >> endobj 118 0 obj << /K [ 11 ] /Pg 5 0 R /P 121 0 R /Type/StructElem/S/mi >> endobj
116 0 obj << /K [ 10 ] /Pg 5 0 R /P 121 0 R /Type/StructElem/S/mo /A<> >> endobj 114 0 obj << /K [ 9 ] /Pg 5 0 R /P 121 0 R /Type/StructElem/S/mi >> endobj ... ... 112 0 obj << /K [ ... 120 0 R ... ] /P 110 0 R /Type/StructElem/S/Formula /ID(Math0.1)/T(InlineMath 0.1) /AF [27 0 R 29 0 R] /A <> >> endobj\end{multicols}} \removelastskip} \vrule height \ht0 width 0pt \removelastskip \leavevmode (a) PDF coding of the /Formula structure node showing the reference to `Associated Files' via the /AF key in object 112. The indirect references (27 and 29) correspond to /Filespec dictionaries, as shown in Fig. 2.1.1. (In the coding ` …' indicates parts omitted due to not being relevant to this structure; these portions are discussed in Sect. 4.) The corresponding marked content is specified via the /K [ ... ] numbers (9, 10, 11) in the child structure nodes; i.e., objects 114 (
< mi>), 116 (< mo>) and 118 (< mi>),
which are children of object 121 (< mrow>) under object 120 (< math>).
\subfiglabel{1b}
\setbox0=\vbox{\hsize=\linewidth
{\scriptsize
\begin{multicols}2
/mi </Alt( k ) >>BDC BT /F30 10.9091 Tf [(k)]TJ ET EMC 1 0 0 1 6.023 0 cm /mo </Alt( as element of ) >>BDC 1 0 0 1 3.03 0 cm BT /F33 10.9091 Tf [(2)]TJ ET EMC 1 0 0 1 10.303 0 cm /mi </Alt( real numbers ) >>BDC BT /F42 10.9091 Tf [(R)]TJ ET EMC\end{multicols} }\removelastskip} \vrule height \ht0 width 0pt (b) Portion of the PDF page content stream showing the /MCID numbers (9, 10, 11) of the actual content portions of the mathematical expression. These correspond to leaf-nodes of the structure tree as presented in part \subfigref[(a)]{1a}. \baselineskip
Subsection 2.1Tagging within PDF documents
Two types of tagging can be employed within PDF files.
`Tagged PDF' documents use both,
with content tags connected as leaf-nodes of the structure tree.
\paragraph*{Tagging of content} is done as
/\(\BNF{tag}\ \BNF{dict}\) BDC … EMC
within a contents stream.
Here the BDC and EMC stand for `Begin Dictionary Content'
and `End Marked Content' respectively,
with the \(\BNF{dict}\) providing key-value pairs that specify `properties' of the marked content,
much like `attributes' in XML or HTML taggingnote.
The \(\BNF{tag}\) can in principle be any PDF name;
however, in §14.6.1 of the specifications [PDF17, ISO32000] it stipulates that
"All such tags shall be registered with Adobe Systems (see Annex E)
to avoid conflicts between different applications marking the same content stream."
Thus one normally uses a standard tag, such as /Span,
or in the presence of structure tagging (see below) choose the same tag name as for the parent structure node.
Figures \subfigref{1b},
\subfigref{3a},
\subfigref{5a}
show the use of Presentation-MathML content tag names,
which are expected to be supported in PDF 2.0 [PDF20].
Typical attributes are the /ActualText and /Alt strings, which allow replacement text to be used
when content is extracted from the document using \textsf{Copy}/\textsf{Paste} or as `Accessible Text' respectively.
The /MCID attribute allows marked content to be linked to document structure, as discussed below.
A variant of this
tagging uses a named resource for the \(\BNF{dict}\) element.
This is illustrated with /AF content tagging in Sect. 3.2.
\paragraph*{Tagging of structure} requires building a tree-like structural description of a document's contents, in terms of Parts, Sections, Sub-sections, Paragraphs, etc. and specialised structures such as Figures, Tables, Lists, List-items, and more [PDF17, ISO32000]. Each structure node is a dictionary of type /StructElem having keys /S for the structure type, /K an array of links to any child nodes (or Kids) including marked content items, and /P an indirect reference to the parent node. Optionally there can be a /Pg key specifying an indirect reference to a /Page dictionary, when this cannot be deduced from the parent or higher ancestor. Also, the /A key can be used to specify attributes for the structure tag when the document's contents are exported in various formats; e.g., using `\textsf{Save As Other ... XML 1.0}' export from Adobe's `Acrobat Pro' browser/editor. Fig. \subfigref{1a} shows the MathML tagging of some inline mathematical content. The tree structure is indicated with lines connecting nodes to their kids; reverse links to parents are not drawn, as this would unduly clutter the diagram. Other keys, such as /ID and /T can provide an identifier and title, for use primarily in editing software to locate specific nodes within appropriately ordered listings.
The link between structure and marked content (as leaf-nodes to the structure tree, say) is established using the /MCID number attribute. A numeric integer entry in the /K Kids array corresponds to an /MCID number occurring within the contents stream for that page specified via a /Pg entry, either of the structure node itself or the closest of its ancestors having such a key. Fig. \subfigref{1b} shows this linking via /MCID with lines drawn to the corresponding structure nodes shown in Fig. \subfigref{1a}. The interplay of structure with content was addressed in the author's paper [DML2009], with Figure 1 of that paper giving a schematic view of the required PDF structural objects.
 \setbox0=\kern-15pt\lower\ht0\box0
\ht0=0pt \dp0=0pt \box0
\setbox0=\vbox{\hsize=\linewidth
{\scriptsize
\setbox0=\kern-15pt\lower\ht0\box0
\ht0=0pt \dp0=0pt \box0
\setbox0=\vbox{\hsize=\linewidth
{\scriptsize
1860 0 obj <> endobj} {\scriptsize \begin{multicols}2
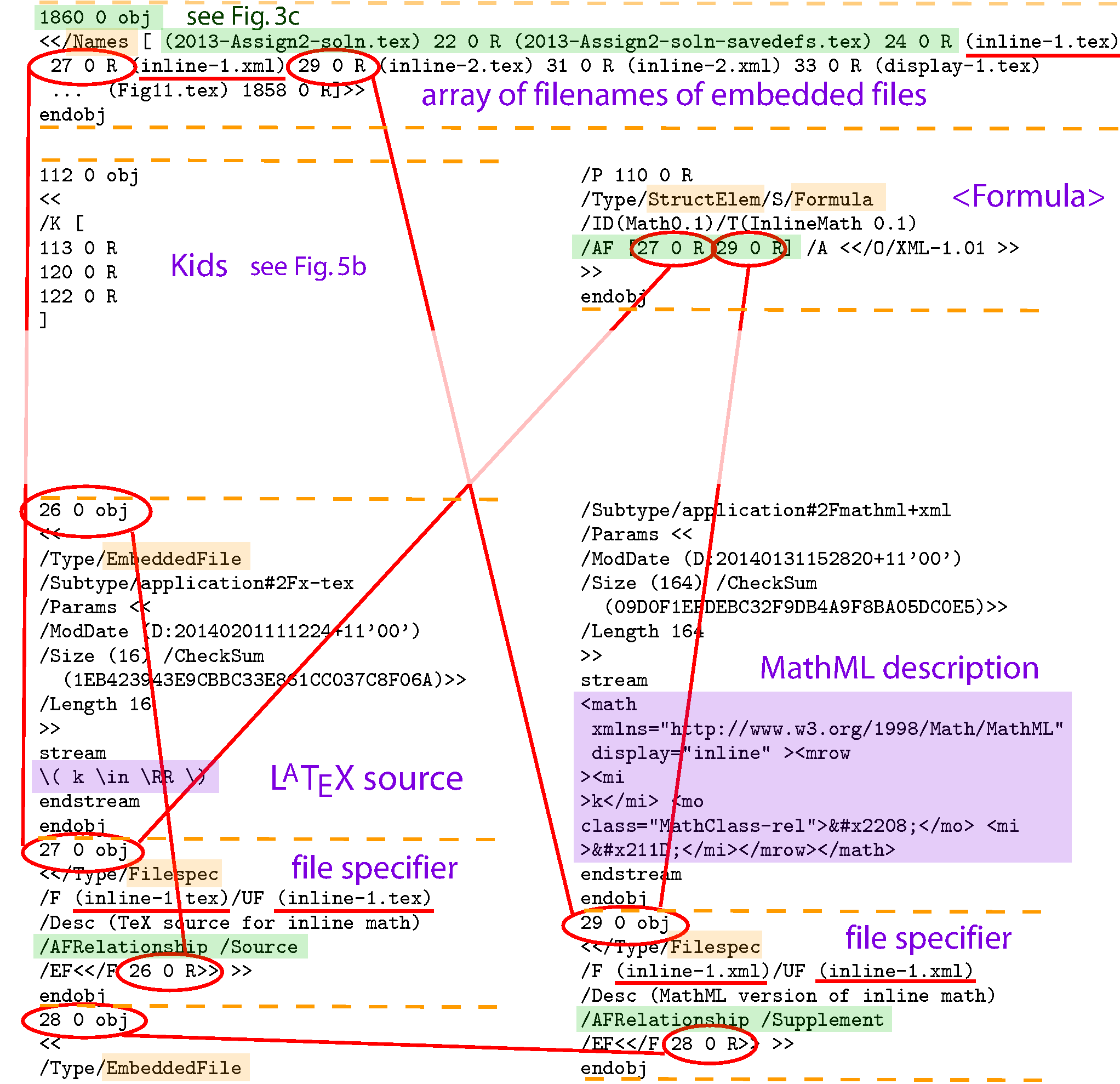
112 0 obj << /K [ 113 0 R 120 0 R 122 0 R ] /P 110 0 R /Type/StructElem/S/Formula /ID(Math0.1)/T(InlineMath 0.1) /AF [27 0 R 29 0 R] /A <> >> endobj\end{multicols}} \removelastskip } \vrule height \ht0 width 0pt \removelastskip \baselineskip \leavevmode (b) A portion of the PDF coding of the /Names array (upper) for embedded files, and coding of the /Formula structure element (lower), showing the /AF key with array of two `Associated' files given as indirect references. The /Names array is used to produce the listing in \subfigref[(a)]{2a} and provides indirect links to /Filespec entries, as shown in \subfigref[(c)]{2c}. \subfiglabel{2c} \setbox0=\vbox{\hsize=\linewidth {\scriptsize \begin{multicols}2
26 0 obj
<<
/Type/EmbeddedFile
/Subtype/application#2Fx-tex
/Params <<
/ModDate (D:20140201111224+11'00')
/Size (16) /CheckSum
(1EB423943E9CBBC33E861CC037C8F06A)>>
/Length 16
>>
stream
\begin{equation} k \in \RR
\end{equation}
endstream
endobj
27 0 obj
<> >>
endobj
28 0 obj
<<
/Type/EmbeddedFile
/Subtype/application#2Fmathml+xml
/Params <<
/ModDate (D:20140131152820+11'00')
/Size (164) /CheckSum
(09D0F1EFDEBC32F9DB4A9F8BA05DC0E5)>>
/Length 164
>>
stream
endstream
endobj
29 0 obj
<> >>
endobj
\end{multicols}}
\removelastskip
}
\vrule height \ht0 width 0pt
\leavevmode
(c)
PDF source of /Filespec dictionaries and /EmbeddedFile objects
which hold the streams of LATEX and MathML coding for the mathematical content
indicated in \subfigref[(a)]{2a}.